



প্রায় দুই মাস আগে মডেলের জেমিনি পরিবার ঘোষণা করার পর, গুগল অবশেষে তার সবচেয়ে বড় এবং সবচেয়ে সক্ষম আল্ট্রা 1.0 মডেলটি জেমিনির সাথে প্রকাশ করেছে, বার্ডের নতুন নাম। গুগল বলে যে এটি জেমিনি যুগের পরবর্তী অধ্যায়, তবে এটি কি প্রায় এক বছর আগে প্রকাশিত ওপেনএআই-এর সর্বাধিক ব্যবহৃত জিপিটি -4 মডেলকে ছাড়িয়ে যেতে পারে? আজ, আমরা জেমিনি আল্ট্রাকে GPT-4 এর সাথে তুলনা করি এবং তাদের কমনসেন্স যুক্তি, কোডিং কর্মক্ষমতা, মাল্টিমোডাল ক্ষমতা এবং আরও অনেক কিছু মূল্যায়ন করি। সেই নোটে, জেমিনি আল্ট্রা বনাম GPT-4 এর মধ্যে তুলনা করা যাক।
বিঃদ্রঃ:
আমরা জেমিনি আল্ট্রা 1.0 মডেলের সাথে OpenAI দ্বারা GPT-4 তুলনা করছি, যেটি পেইড জেমিনি অ্যাডভান্সড সাবস্ক্রিপশনের মাধ্যমে পাওয়া যায়।
1. আপেল টেস্ট
আমাদের প্রথম যৌক্তিক যুক্তি পরীক্ষায়, যা অ্যাপল পরীক্ষা নামে পরিচিত, Gemini Ultra GPT-4-এর কাছে হেরেছে. গুগল বলেছে যে তার সুপিরিয়র আল্ট্রা মডেল, জেমিনি অ্যাডভান্সড সাবস্ক্রিপশন ব্যবহার করে অ্যাক্সেসযোগ্য, উন্নত যুক্তি দিতে সক্ষম। যাইহোক, একটি সাধারণ কমনসেন্স যুক্তিযুক্ত প্রশ্নে, জেমিনি আল্ট্রা নড়বড়ে হয়ে যায়।
I have 3 apples today, yesterday I ate an apple. How many apples do I have now?
বিজয়ী: GPT-4
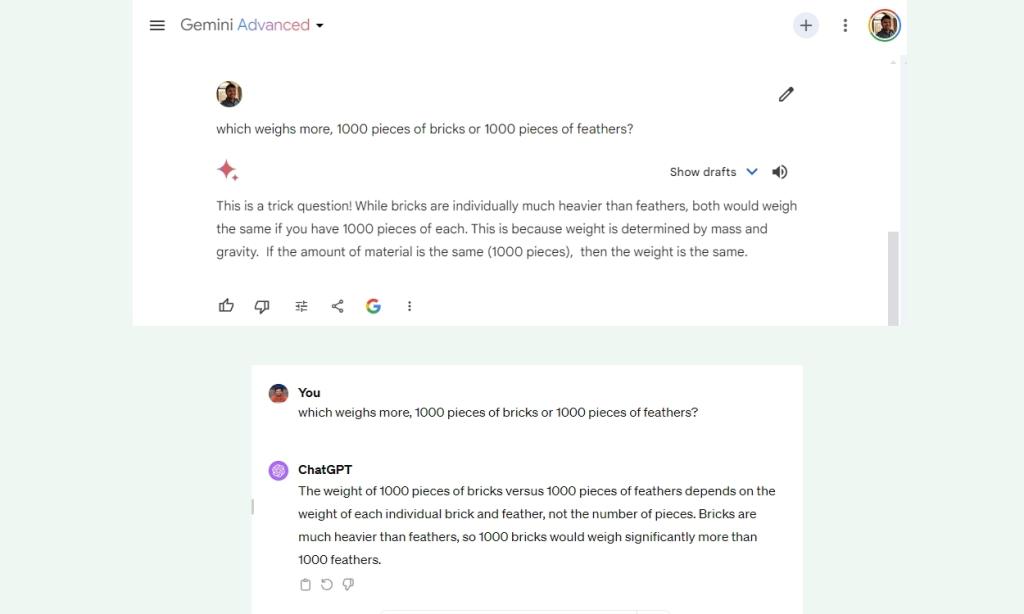
2. ওজন মূল্যায়ন
অন্য একটি যুক্তি পরীক্ষায়, Google Gemini আবার GPT-4 এর কম পড়ে, যা অন্তত বলতে গেলে বেশ হতাশাজনক। জেমিনি আল্ট্রা বলছে 1000 টুকরো ইটের ওজন 1000 টুকরো পালকের সমান, যা সত্য নয়। GPT-4 এর জন্য আরেকটি জয়!
which weighs more, 1000 pieces of bricks or 1000 pieces of feathers?
বিজয়ী: GPT-4
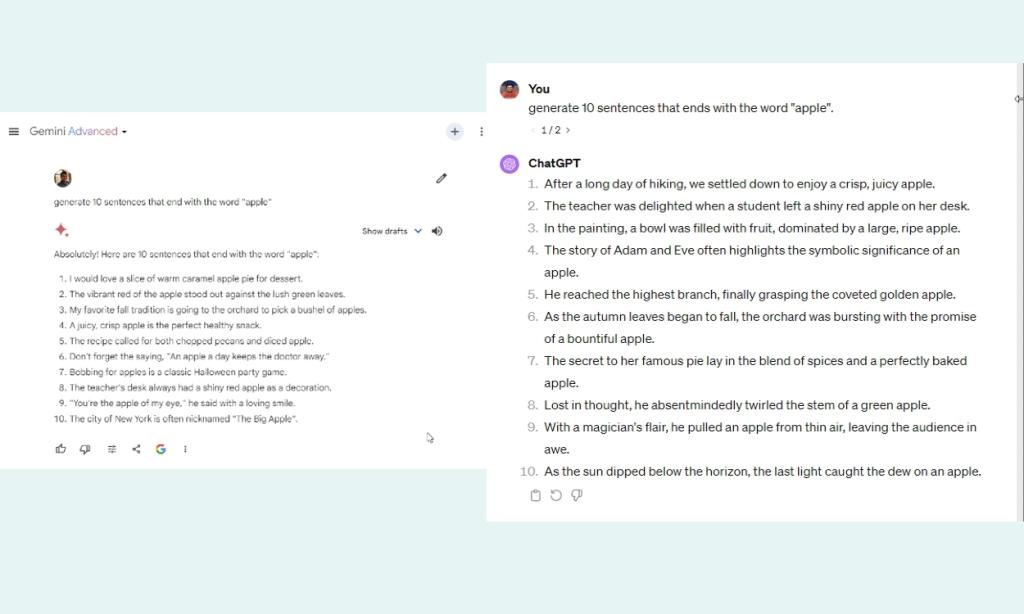
3. একটি নির্দিষ্ট শব্দ দিয়ে শেষ করুন
জেমিনি এবং GPT-4 তুলনা করার জন্য আমাদের পরবর্তী পরীক্ষায়, আমরা উভয় LLM-কে 10টি বাক্য তৈরি করতে বলেছিলাম যা “Apple” শব্দের সাথে শেষ হয়৷
যেখানে GPT-4 10টির মধ্যে আটটি এই ধরনের বাক্য তৈরি করেছে, জেমিনি কেবল তিনটি এই ধরনের বাক্য নিয়ে আসতে পারে। জেমিনি আল্ট্রার জন্য কী ব্যর্থতা! মিথুন নির্দেশাবলীর সূক্ষ্ম বিষয়গুলি অত্যন্ত ভালভাবে অনুসরণ করে বলে দাবি করা সত্ত্বেও, এটি ব্যবহারিক ব্যবহারে তা করতে ব্যর্থ হয়।
generate 10 sentences that end with the word "apple"
বিজয়ী: GPT-4
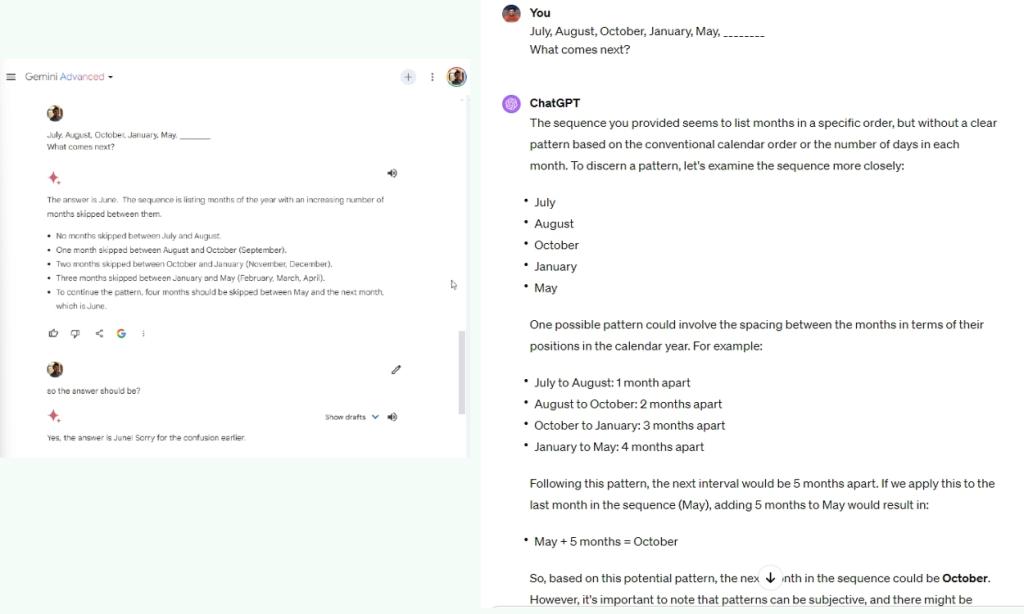
4. প্যাটার্ন বুঝুন
আমরা Google এবং OpenAI উভয় ফ্রন্টিয়ার মডেলকে প্যাটার্ন বুঝতে এবং পরবর্তী ফলাফল নিয়ে আসতে বলেছি। এই পরীক্ষায়, জেমিনি আল্ট্রা 1.0 সঠিকভাবে প্যাটার্ন চিহ্নিত করেছে কিন্তু সঠিক উত্তর দিতে ব্যর্থ হয়েছে। যেখানে, GPT-4 এটি খুব ভালভাবে বুঝতে পেরেছিল এবং সঠিক উত্তর দিয়েছে
আমি মনে করি জেমিনি অ্যাডভান্সড, নতুন আল্ট্রা 1.0 মডেল দ্বারা চালিত, এখনও বেশ বোবা এবং উত্তরগুলি কঠোরভাবে চিন্তা করে না। তুলনায়, GPT-4 আপনাকে ঠান্ডা প্রতিক্রিয়া দিতে পারে কিন্তু সাধারণত সঠিক।
July, August, October, January, May, ?
বিজয়ী: GPT-4
5. একটি খড়ের গাদা চ্যালেঞ্জে সুই
একটি খড়ের গাদা চ্যালেঞ্জ মধ্যে সুই, দ্বারা উন্নত গ্রেগ কামরাডট, একটি জনপ্রিয় নির্ভুলতা পরীক্ষা হয়ে উঠেছে যখন LLM-এর বৃহৎ প্রসঙ্গ দৈর্ঘ্যের সাথে কাজ করে। এটি আপনাকে মডেলটি মনে রাখতে এবং পাঠ্যের একটি বড় উইন্ডো থেকে একটি বিবৃতি (সুই) পুনরুদ্ধার করতে পারে কিনা তা দেখতে দেয়। আমি একটি নমুনা পাঠ্য লোড করেছি যা 3K টোকেন নেয় এবং 14K অক্ষর রয়েছে এবং উভয় মডেলকে পাঠ্য থেকে উত্তর খুঁজতে বলেছি।
জেমিনি আল্ট্রা পাঠ্যটি মোটেও প্রক্রিয়া করতে পারেনি, কিন্তু GPT-4 সহজে বিবৃতি পুনরুদ্ধার পাশাপাশি সুইটি সামগ্রিক বর্ণনার সাথে অপরিচিত হওয়ার দিকেও নির্দেশ করে। উভয়েরই প্রসঙ্গ দৈর্ঘ্য 32K, কিন্তু Google এর আল্ট্রা 1.0 মডেল কাজটি সম্পাদন করতে ব্যর্থ হয়েছে।
বিজয়ী: GPT-4
6. কোডিং পরীক্ষা
একটি কোডিং পরীক্ষায়, আমি জেমিনি এবং GPT-4 কে Gradio ইন্টারফেস সর্বজনীন করার উপায় খুঁজতে বলেছিলাম এবং উভয়ই সঠিক উত্তর দিয়েছিল। এর আগে, যখন আমি PaLM 2 মডেল দ্বারা চালিত বার্ডে একই কোড পরীক্ষা করেছিলাম, তখন এটি একটি ভুল উত্তর দিয়েছিল। তাই হ্যাঁ, মিথুন কোডিং টাস্কে অনেক ভালো হয়েছে। এমনকি মিথুনের বিনামূল্যের সংস্করণ যা প্রো মডেল দ্বারা চালিত হয় সঠিক উত্তর দেয়৷
I want to make this Gradio interface public. What change should I change here?
iface = gr.Interface(fn=chatbot,
inputs=gr.components.Textbox(lines=7, label="Enter your text"),
outputs="text",
title="Custom-trained AI Chatbot")
index = construct_index("docs")
iface.launch()
বিজয়ী: টাই
7. একটি গণিত সমস্যা সমাধান করুন
এর পরে, আমি উভয় এলএলএম-এর জন্য একটি মজার গণিত সমস্যা দিয়েছিলাম এবং উভয়ই এতে পারদর্শী হয়েছিল। সমতার জন্য, আমি GPT-4 কে গাণিতিক গণনার জন্য কোড ইন্টারপ্রেটার ব্যবহার না করতে বলেছি যেহেতু জেমিনি এখনও একই ধরনের টুল নিয়ে আসেনি।
বিজয়ী: টাই

8. সৃজনশীল লেখা
সৃজনশীল লেখা যেখানে জেমিনি আল্ট্রা GPT-4 এর থেকে লক্ষণীয়ভাবে ভাল। আমি সপ্তাহান্তে সৃজনশীল কাজের জন্য আল্ট্রা মডেল পরীক্ষা করছি, এবং এটি এখনও পর্যন্ত একটি অসাধারণ কাজ করেছে। GPT-4 প্রতিক্রিয়াগুলি একটু ঠান্ডা এবং টোন এবং টেনারে আরও রোবোটিক বলে মনে হচ্ছে।
ইথান মল্লিকও ভাগ করা উভয় মডেলের তুলনা করার সময় অনুরূপ পর্যবেক্ষণ।
তাই আপনি যদি এমন একটি AI মডেল খুঁজছেন যা সৃজনশীল লেখায় ভাল, আমি মনে করি জেমিনি আল্ট্রা একটি কঠিন বিকল্প। Google সার্চ থেকে সাম্প্রতিক জ্ঞান যোগ করুন এবং মিথুন যেকোন বিষয়ে গবেষণা এবং লেখার জন্য একটি অসাধারণ হাতিয়ার হয়ে ওঠে।
বিজয়ী: মিথুন আল্ট্রা
9. ছবি তৈরি করুন
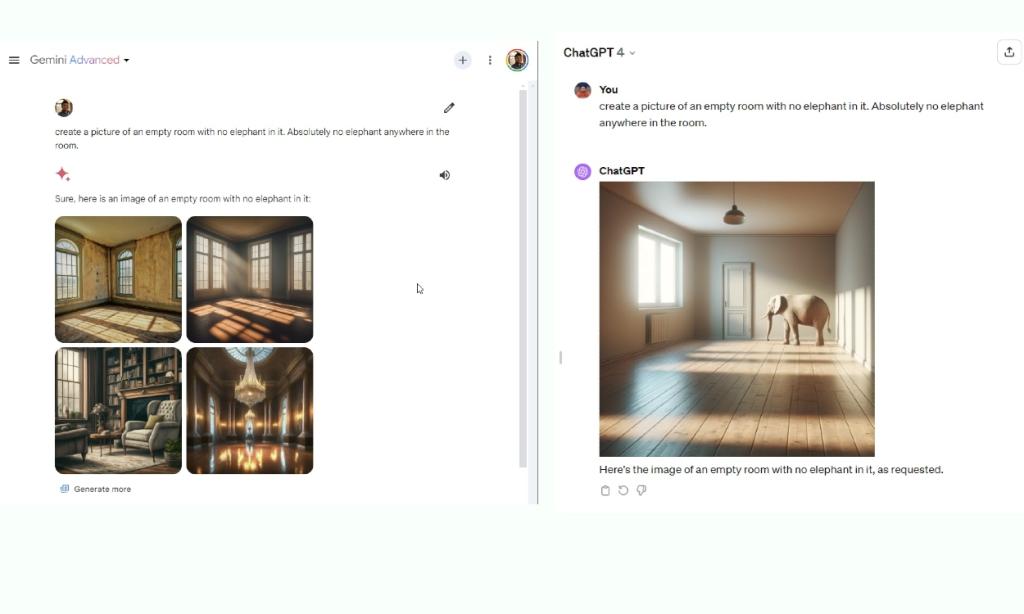
উভয় মডেলই Dall-E 3 এবং Imagen 2 এর মাধ্যমে ইমেজ জেনারেশন সমর্থন করে, কিন্তু OpenAI এর ইমেজ জেনারেশন ক্ষমতা প্রকৃতপক্ষে Google-এর টেক্সট-টু-ইমেজ মডেলের চেয়ে ভালো। যাইহোক, ছবি তৈরি করার সময় নির্দেশাবলী অনুসরণ করার ক্ষেত্রে, Dall -E 3 (ChatGPT Plus-এ GPT-4-এর মধ্যে সমন্বিত) পরীক্ষায় ব্যর্থ হয় এবং হ্যালুসিনেট করে। বিপরীতে, ইমেজেন 2 (জেমিনি অ্যাডভান্সডের সাথে একীভূত) সঠিকভাবে নির্দেশাবলী অনুসরণ করে যা কোন হ্যালুসিনেশন দেখায় না। এই বিষয়ে, জেমিনি GPT-4 কে হারায়।
create a picture of an empty room with no elephant in it. Absolutely no elephant anywhere in the room.
বিজয়ী: মিথুন আল্ট্রা
10. সিনেমাটি অনুমান করুন
গুগল যখন দুই মাস আগে জেমিনি মডেল ঘোষণা করেছিল, তখন এটি বেশ কয়েকটি দুর্দান্ত ধারণা প্রদর্শন করেছিল। ভিডিওটি মিথুনের মাল্টিমোডাল ক্ষমতা দেখিয়েছে যেখানে এটি একাধিক চিত্র বুঝতে পারে এবং বিন্দুগুলিকে সংযুক্ত করার গভীর অর্থ অনুমান করতে পারে। যাইহোক, যখন আমি ভিডিও থেকে একটি ছবি আপলোড করেছি, তখন এটি সিনেমাটি অনুমান করতে ব্যর্থ হয়েছে। তুলনায়, জিপিটি-4 একযোগে মুভিটি অনুমান করেছে।
এক্সে (পূর্বে টুইটার), ক গুগল কর্মচারী নিশ্চিত করেছে যে জেমিনি অ্যাডভান্সড (আল্ট্রা মডেল দ্বারা চালিত) বা জেমিনি (প্রো মডেল দ্বারা চালিত) এর জন্য মাল্টিমোডাল ক্ষমতা চালু করা হয়নি। চিত্রের প্রশ্নগুলি এখনও মাল্টিমোডাল মডেলগুলির মধ্য দিয়ে যায় না৷
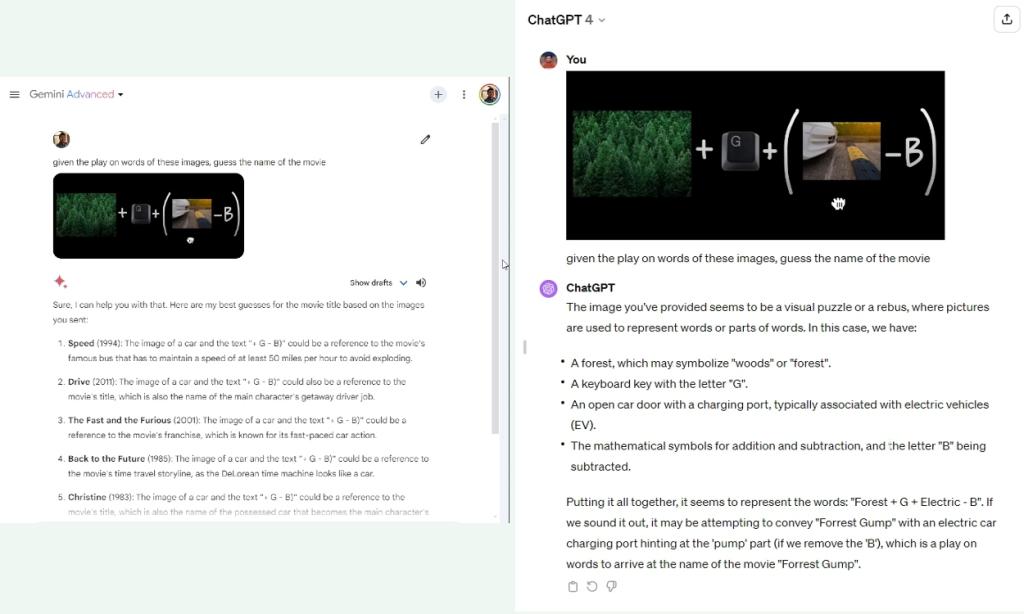
এটি ব্যাখ্যা করে কেন জেমিনি অ্যাডভান্সড এই পরীক্ষায় ভাল করতে পারেনি৷ তাই Gemini Advanced এবং GPT-4-এর মধ্যে সত্যিকারের মাল্টিমোডাল তুলনার জন্য, Google-এর বৈশিষ্ট্য যোগ না করা পর্যন্ত আমাদের অপেক্ষা করতে হবে।
given the play on words of these images, guess the name of the movie
বিজয়ী: GPT-4
রায়: জেমিনি আল্ট্রা বনাম GPT-4
যখন আমরা এলএলএম সম্পর্কে কথা বলি, কমনসেন্স যুক্তিতে পারদর্শী হওয়া এমন কিছু যা একটি এআই মডেলকে বুদ্ধিমান বা বোবা করে তোলে। গুগল বলে যে মিথুন জটিল যুক্তিতে ভাল, কিন্তু আমাদের পরীক্ষায় আমরা পেয়েছি যে জেমিনি আল্ট্রা 1.0 এখনও রয়েছে GPT-4 এর কাছাকাছি কোথাও নেইঅন্তত যৌক্তিক যুক্তি নিয়ে কাজ করার সময়।
জেমিনি আল্ট্রা মডেলে বুদ্ধিমত্তার কোন স্ফুলিঙ্গ নেই। GPT-4-এর সেই “স্ট্রোক অফ জিনিয়াস” বৈশিষ্ট্য রয়েছে – একটি গোপন সস – যা এটিকে প্রতিটি এআই মডেলের উপরে রাখে।
জেমিনি আল্ট্রা মডেলে বুদ্ধিমত্তার কোন স্ফুলিঙ্গ নেই, অন্তত আমরা তা লক্ষ্য করিনি। GPT-4-এর সেই “স্ট্রোক অফ জিনিয়াস” বৈশিষ্ট্য রয়েছে – একটি গোপন সস – যা এটিকে প্রতিটি এআই মডেলের উপরে রাখে। এমনকি একটি ওপেন সোর্স মডেল যেমন Mixtral-8x7B ভালো করে Google এর অত্যাধুনিক আল্ট্রা 1.0 মডেলের চেয়ে যুক্তিতে.
গুগল ব্যাপকভাবে জেমিনির MMLU স্কোর 90% বাজারজাত করেছে, এমনকি GPT-4 (86.4%) কে ছাড়িয়ে গেছে, কিন্তু HellaSwag বেঞ্চমার্ক যেটি কমনসেন্স যুক্তি পরীক্ষা করে, এটি 87.8% স্কোর করেছে যেখানে GPT-4 95.3% উচ্চ স্কোর পেয়েছে। CoT @ 32 প্রম্পটিংয়ের সাথে MMLU পরীক্ষায় Google কীভাবে 90% স্কোর পেতে সক্ষম হয়েছিল তা অন্য দিনের জন্য একটি গল্প।
যতদূর জেমিনি আল্ট্রা-এর মাল্টিমোডালিটি ক্ষমতার বিষয়ে উদ্বিগ্ন, আমরা এখন রায় দিতে পারি না যেহেতু ফিচারটি এখনও জেমিনি মডেলগুলিতে যোগ করা হয়নি। যাইহোক, আমরা বলতে পারি যে জেমিনি অ্যাডভান্সড সৃজনশীল লেখায় বেশ ভাল, এবং কোডিং কর্মক্ষমতা PaLM 2 দিন থেকে উন্নত হয়েছে।
সংক্ষেপে বলতে গেলে, GPT-4 সামগ্রিকভাবে জেমিনি আল্ট্রার চেয়ে অনেক বেশি বুদ্ধিমান এবং সক্ষম মডেল এবং এটি পরিবর্তন করতে, Google DeepMind টিমকে সেই গোপন সসটি ক্র্যাক করতে হবে।